主页 > imtoken交易所在哪里 > 什么是utxo
什么是utxo
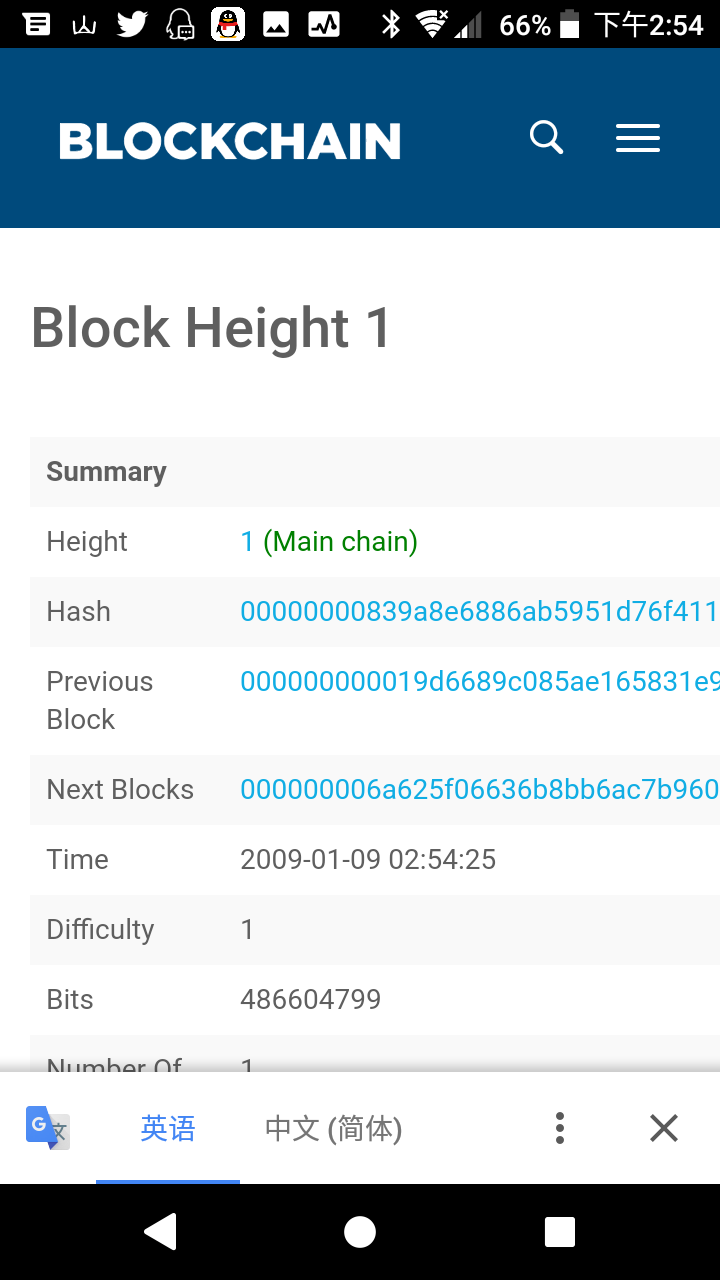
UTXO 代表未花费的交易输出。
在比特币社区中,Transaction简称为TX,所以上面的短语简称为UTXO。 一般认为UTXO是比特币区块链设计的一部分,但实际上UTXO与区块链没有必然联系。 您可以在不使用 UTXO 的情况下完全复制比特币区块链。
HyperLedger和Ethereum一开始并没有采用UTXO,现在前者已经切换回UTXO,而后者有意加入这个选项。 我想这也是中本聪擅长的地方——后来者抄袭,中间想做一些小的改进,后来做了之后,发现原来的版本还是很高的,又改回来了相继...
那么UTXO到底是什么?
前不久听了《卓老板谈技术》的插曲《比特币》,讲的是比特币的支付流程。 他说他要付给他奶茶妹妹5个比特币,于是系统从他的账户里扣了5个比特币。 ,给奶茶姐姐的账户加5,然后把这笔交易记入区块链账本,完成。 这部剧虽然拍的不错,但是在这一点上,卓总却完全看错了。 他描述的是一种基于账户的方案,而不是比特币实际采用的UTXO方案。
如果要设计一个支付系统,我们肯定会想到和卓老板一起,给张三一个余额为100元的账户,给李四一个余额为50元的账户。 当张三要付给李四20块钱时,进行如下操作:
1、查看张三账户余额是否充足,如果不足20元,交易将终止,张三会报“余额不足”
2、从张三的账户中扣除20元(假设手续费为零)
3.给李四的账户充值20元
无论是银行、信用卡、证券交易系统,还是互联网第三方支付系统,其核心都是基于账户(account based)设计,以关系数据库为支撑。
数据库必须保证两点。 首先是要保证商业规则的遵守,张三要有足够的余额。 二是保证事务性,即原子性、一致性、隔离性和持久性(ACID)。 这些都是数据库的常识性知识,这里就不赘述了。 这种基于账户的设计简单直观,在IT系统设计中已经使用了几十年,应该说是没有问题的。

但是比特币并不是设计成基于账户的系统,而是发明了 UTXO 方案。
要理解UTXO,最简单的方法就是描述一个比特币从诞生到在商业世界中沉浮的经历。 我们假设这样一个场景:张三挖出了12.5个比特币。 几天后,他将其中的2.5付给了李四。 几天后,他和李四各出资2.5个比特币凑成5个比特币支付给王五。
如果是基于账号的设计,张、李、王在数据库中各有一个账号,三人的账号变化如下图所示:
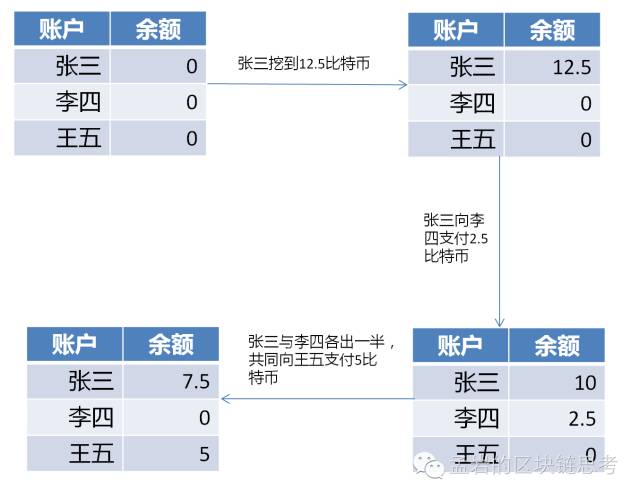
但是在比特币中,这个过程是通过UTXO实现的,如下图:
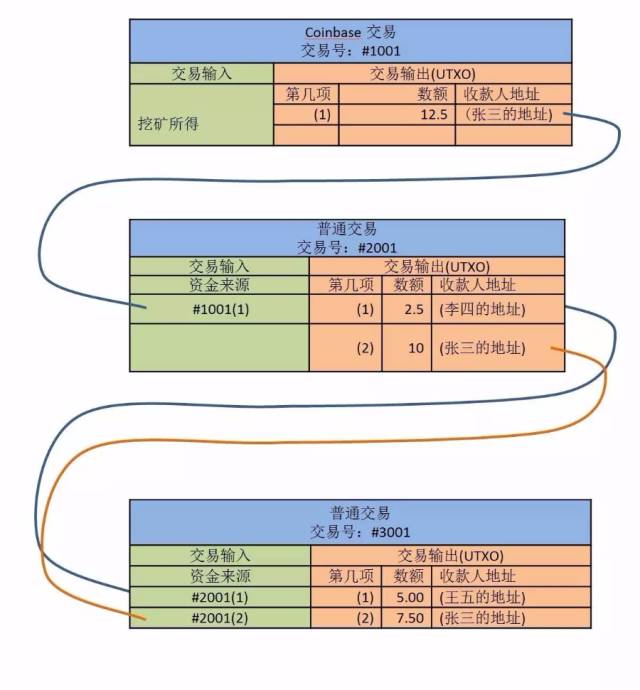
比特币的区块链账本记录着一笔一笔的交易。
每笔交易都有若干交易输入,即资金来源,以及若干交易输出,即资金去向。 一般来说,每笔交易都需要花费(spend)一个输入并产生一个输出,而产生的输出就是“未花费的交易输出”,即UTXO。
比特币交易遵循几条规则。
第一,除了coinbase交易,所有的资金来源都必须来自之前一笔或几笔交易的UTXO,就像水管一样,一个接一个,一个进一个进一个进出,生生不息,Money交易之间流动。
其次,任何一笔交易中交易输入的总量必须等于交易输出的总量,等式两边必须平衡。
上图中的第一笔交易#1001 是一笔 coinbase 交易。 比特币是由矿工开采的。 当矿机好不容易找到一个合格的区块后,它就获得了创建一个coinbase交易的特权,在里面放入新的金额,交易输出的收款人地址在第一栏,把你的地址写成正方式。 在我写这篇文章的那天(2016年8月9日),这个比特币的数量是12.5枚,市场价格是48576元人民币。 这笔coinbase交易随着张三挖出的区块被各个节点接受,经过六次确认后将永远铭刻在历史中。
几天后,张三打算支付给李四2.5个比特币,张三发起一笔#2001交易,这笔交易的资金来源为“#1001(1)”,即#1001交易——第一笔张三挖出的coinbase交易的UTXO。 然后在本次交易的交易输出UTXO项中,设置2.5个比特币的收款人地址为李四的地址。
请注意,本次交易必须消耗掉之前产生的12.5个比特币的所有输出项,而由于张三只打算支付给李四2.5个比特币,所以为了消耗掉剩余的10个比特币,他必须要支付剩余的10个比特币来我自己,从而遵守输入输出平衡的规则。
过几天,张三和李四打算结合AA系统,给王五支付5个比特币。 然后张三或李四发起交易#3001。 在交易输入部分,有两个资金来源,分别是#2001(1)和#2001(2),分别代表第(1)和第(2)项UTXO。 然后在这笔交易的输出部分做同样的事情,给王五5个比特币,剩下的7.5个比特币还给张三。 如果王五以后要花掉他的5个比特币,他必须在交易中注明资金来源#3001(1)。
所以,实际上,没有比特币,只有UTXO。 我们说张三拥有10个比特币,我其实是说在现在的区块链账本中,几笔交易的UTXO项目的收款人都是张三的地址写的,而这些UTXO项目的金额总和就是10。因为在在比特币系统中,一个人可以拥有的地址资源是取之不尽,用之不竭的。 如果你想知道你在大量地址中收集了多少UTXO,人类是不可能计算出来的,需要你用比特币钱包代为跟踪计算。
以上就是UTXO的简单介绍。
那么UTXO高在哪里呢?
比特币的很多技术点都不是中本聪独创的。 例如,基于“Proof-of-Work”的共识机制是由 Adam Back 在 Hashcash 中提出的。 Wei Dai 的 b-money 和 Nick Szabo 的 Bitgold 提出了所有交易都包含在一个账本中并加上时间戳以防止双花攻击(double-spend attack)的想法,更何况比特币网络是一个零优化的泛滥灌溉 P2P网络。 就P2P技术而言,很多方面还落后于2001年出现的BitTorrent。
但是有三个技术点是中本聪绝对独创的,一是区块链的设计,一是UTXO,三是智能合约。 而这三项设计都极为天才,被斯坦福大学密码学与计算机安全教授丹博内评价为“极其出色”,“必将激发无穷无尽的创新”。
当然,中本聪最了不起的并不是这三个单点创新,而是将所有这些技术点与加密货币本身的特性相结合,设计了一套“惩恶扬善”的经济激励体系”。 将技术创新和系统设计结合到一个无缝系统中。
在这个系统中,任何人都可以建立一个匿名节点,编写破坏性代码,然后进行匿名攻击。 即使攻击成功,窃取大量财富,身份也不会暴露,可以逍遥法外。
这个系统是赤裸裸的,对窃贼开放,并允许你攻击和摧毁它。 即使你成功突破防线,窃取了大量财富,整个比特币系统不仅不会惩罚你,还会牢牢保护你的赃款。 然后悬赏100亿美元,一跑就是七年。 到目前为止,还没有对主区块链的攻击成功,甚至没有一次。
中本聪将比特币设计得像数学原理一样优美,很多后来者甚至无法复制到这个程度。 我想这就是加州大学洛杉矶分校金融学教授 Bhagwan Chowdhry 提名中本聪作为 2016 年诺贝尔经济学奖候选人的原因。 相信中本聪在比特币方面的很多设计思想,以及整个比特币开发者社区所做的很多改进,不仅是区块链的创举,也将成为IT系统设计创新思想的源泉.

UTXO的设计值得深思。 其设计方案在《什么是UTXO》一文中有介绍。 本文讨论 UTXO 的优点和缺点。
为什么中本聪要这样设计比特币? 考虑到他应该不是未来穿越回来的角色,按常理推断他一开始应该也是从账户制设计的,但后来他决定改用UTXO方案,并且他一定是遇到了什么问题。
不幸的是,在比特币的源代码中找不到这些问题的答案。 比特币的发展始于2007年5月,Github上最早的比特币源代码版本是中本聪于2009年9月16日推出的0.1.5版本,但UTXO的设计已经初具规模。
后来,有人翻出了他的旧邮件,找到了 2008 年 9 月版比特币的代码。 该代码是在比特币区块链上线前几周发布的,应该与比特币创世纪运行的版本非常接近。 但是仔细一看,UTXO也已经敲定了。 我们注定无法通过代码研究来发现UTXO的设计脉络。
其他文学呢? 它也不起作用。 中本聪在发布比特币之前,主要是和一些密码学专家往来邮件,而这些邮件是外界看不到的。 他积极参与论坛讨论,主要是在比特币发布之后。 在UTXO设计的形成过程中,我找不到他的任何言论。
由于这些方法都不起作用,我们只能猜测。
我猜中本聪最初设计比特币的时候,也是采用了账户方案。 但在 2007 年下半年或 2008 年上半年的某个时候,中本聪发现基于账户的方案存在问题,于是他创建了 UTXO 方案。

那么基于账户的解决方案存在哪些问题呢?
如果您采用基于帐户的方法,那么您肯定需要一个数据库。 这个数据库可以让你轻松查看张三和李四的账户余额。
当然,UTXO方案还需要一个数据库,它记录了当前系统中每一笔“未花费的交易输出”,也就是比特币。 当节点收到一笔交易时,需要查询UTXO数据库,查看该笔交易引用的UTXO是否存在,其收款人(所有者)是否为当前新交易的付款人。 事务结束后,需要对数据库进行相应的更新。
首先要明确的是,无论是账户数据库还是UTXO数据库,都必须是去中心化的,每个节点都有克隆,不能是中心化的。 如果比特币系统有一个中央数据库,不管你有多少个节点,每一笔交易都必须去中央数据库进行验证,然后执行“转账”交易操作,那根本就谈不上“去中心化”。 比特币不值钱,还不如老老实实的支付宝。

既然每个节点克隆一个数据库,根据交易流程同步修改,那么账户数据库和UTXO数据库有什么区别呢?
进一步思考,我们会发现还是有很大的不同。
首先,从长远来看,账户数据库会无限扩大,而UTXO数据库会小很多。
要知道,比特币是一个匿名系统,它的账户就是一个“地址”。 每个比特币用户都可以拥有几乎无限的地址。 从比特币系统的角度来看,它不知道这两个地址是否对应于同一个人。
而且,比特币鼓励用户大量开通地址。 有的钱包软件甚至每笔交易都开一个新账户,每次收钱都开一堆账户,分散资金,保证匿名。 这还不算,很多用户出于好奇下载了一个比特币钱包,申请了几十个地址,然后就冷冰冰地躺在那里,再也没有使用过。 或者一些地址被使用过并且再也没有使用过,或者甚至只是被所有者忘记了。 但是所有这些有用的和没用的地址,我们的账户数据库都得牢牢记住。
随着时间的推移,账户数据库中“弃用账户”的比例会越来越大,体积会无限扩大。 这怎么能容忍呢? 要知道,比特币矿机每处理一笔交易,都需要查询这个数据库。 当数据库规模无限扩大时,查询速度也会变慢,延缓比特币矿机的挖矿竞争,这是不可接受的。
相比之下,UTXO 存储了所有“有用”的数据,即当前未被消费的比特币。 矿工需要查询和操作 UTXO 数据库来验证交易。 这个过程一定要快,越快越好,这样才能在挖矿比赛中抢先一步。
得益于 UTXO 方案,比特币至今已经运行了将近八年,整个数据库并不算大。 到 2016 年 5 月,压缩后的体积约为 1.5GB。 估计解压后的体积在8GB左右,完全可以放在内存中。 如果是账号数据库,估计内存早就放不下了。
其次,UTXO 数据库允许并行事务操作。 在账户数据库中,如果张三要转20元给李四,需要进行一次数据库交易,从张三的账户中减去20,在李四的账户中加20。 如果同一时间,王舞要给张三转30块钱,那么这笔交易就得排队,不能并行。
之所以会这样,归根结底是因为两笔交易都需要处理“张三的账户余额”这个共享状态。 然而,在 UTXO 中比特币怎么收款比特币怎么收款,数据库跟踪比特币所有权的转移,而不是账户状态。 不管张三自己在发生多少笔收支交易,这些收支交易都是发生在不同的比特币上。 更重要的是,这些交易不共享任何状态,因此不会相互干扰。 所有这些交易都可以同时执行。 这样做的好处不仅是速度快,更重要的是可扩展和分布式。
在很多大型互联网公司中,处理分布式事务是核心技术竞争力之一。 只有强大的精英技术团队,大量的长期持续的投入和维护与改进,才能在这个领域站稳脚跟。 有没有可能发明一个基于UTXO的技术系统,让交易的交易处理也完全分布式? UTXO 是否有更广泛的适用范围?
比如当你在天比特商城花费10个比特币购买了一件衣服,而智比特宝并没有从你的账户扣款,而是在一次交易中将这件衣服的所有权与10个比特币的所有权互换,让这件衣服的主人衣服从商家换到你,让比特币的主人从你换到商家。
请注意,此过程不会与同时进行的任何其他交易共享状态,并且可以轻松确保逐个交易的交易完整性。 这样的交易过程可以很容易地大规模分布。 交易量大则增加节点,交易量小则减少节点。 在这样的架构下,天币商城和天币宝一天完成的百亿交易,我们不需要兴奋和膜拜,因为从技术上讲这已经不是什么了不起的事情了。 当然,这只是一个猜测。 真的是这样吗? 还有其他坑吗? 这是一个极具吸引力的话题,值得未来深入探讨。
当然,UTXO 也有一些缺点。
首先,UTXO方案不易实现,相对复杂。 这也是为什么以太坊一开始没有采用 UTXO 方案的原因。
第二,UTXO数据库现在也很臃肿。 2015年5月,UTXO数据库压缩后为650MB,解压后内存为4GB。 一年后压缩后体积为1.3GB,解压后占用内存8GB。 没有人能承受今年翻倍的速度。 比特币大师 Galvin Andersen 做了一个估计,到 2025 年,如果要将 UTXO 数据库放入节点内存中,光是购买内存就需要花费 4000 美元。
UTXO 膨胀的问题也让人们担心比特币区块的膨胀。 如果比特币区块从 1MB 扩容到 2MB,那么 UTXO 会加速扩容。
现在有人提出了解决问题的建议,有人说通过激励机制鼓励节点合并UTXO,也有人建议放宽一些验证要求,允许节点将UTXO放到磁盘上。 Peter Todd 提出了完整的提案,有兴趣的可以点击这里()。
我个人在2010年翻阅旧论文堆的过程中看到了一个叫Red的黑客和中本聪的讨论。 Red建议数据库中不要存储当前的UTXO集合,而只存储铸币记录:这些比特币是什么时候被开采出来的,收款人是谁。 然后,每当有一笔交易发生时,钱包软件负责将花费的比特币从被挖出到本次交易的所有交接记录提交给节点,节点只需要验证所有这些记录是否相关对彼此。 如果扣和数字签名匹配,则交易可以被批准。
打个比方,这好比买卖二手房。
政府只有这处房产的地契正本,张三李四的买卖双方需要将地契正本和历史上所有的过户合同一一带上,最终拟定本次买卖合同。来到办公室。 办事员首先从档案中调出房产的原产权契据文件,比对原产权契据,证明此处房产自竣工之日起确实是区政府认可的合法房产,然后核实并更换一个接一个。 手上的合同,看转手的过程是否环环相扣,看签名是否真实,直到最新的合同确认房产确实是张三所有,再去查最新的“张三把这个房产卖给了李某”对于“四”合同,主要是核对签字,当然还要核对其他条件,审核通过后,在板子上加盖公章,批准交易。注意政府这份合同不用备案,应该由李四收回保管,下次李四要把房产卖给王五的时候,连同合同原件一起给衙役看地契为“张三将此房产卖给李四”,证明他确实是当前房产的主人。
该方案的优点是原始造币记录(相当于原始房契)的数量线性增加,每个区块只生成一条这样的记录,因此对应的数据库不会发生扩容。 在所有比特币都被开采之后,数据库停止增长。
缺点是复杂性完全归咎于钱包软件和节点验证过程。 对于每笔交易,钱包都必须向节点提交一份很长且越来越长的比特币易手记录。 节点也需要从这些比特币诞生的那一刻开始逐一验证,交易验证的性能会大大降低。
正是出于这个原因,中本聪当时并没有接受这个提议。 然而,这主要是因为货币流通太快了。 相同的解决方案在其他应用场景中可能是可行的。 所以我在这里详细说明。